Help Center
Expertrec Crawler – Control your Index
Introduction
Crawler is one of the main components of a Site Search. Its main duty is to make available various pieces of content to be indexed. Search operates only on the indexed content. The goal of Expertrec’s crawler is to mirror various things that Google, W3C and various other organisations has helped standardized. If there is a missing standard, Google’s behaviour will be considered as the standard and we will attempt to be as close as possible to it.
Overview
The basic set of operations a crawler does is covered in this section, without getting into the finer details. The finer details will be covered in the later part of the document. The crawler repeatedly goes through the following phases.
- Selection – pick up N urls to be crawled.
- Fetching – URLs are fetched from the respective host servers.
- Content Extraction – various contents are extracted and updated in the index.
- Link Extraction – new URLs are discovered from the fetched urls and made available for the next iteration.
Selection
Among all the URLs that can be fetched, the crawler has to pick N urls (Expertrec uses 50 URLs at a time to crawl). If there are less than 50 URLs, all of them are picked up. If there are more than 50, various prioritization happens and the winning 50 URLs are picked up for fetching. The prioritization algorithm considers among various factors, things like how frequently the document is generally updated, when it was last fetched, the priority value given in the sitemap.xml file, page rank, etc.
Fetching
The URLs are fetched from the host server. Expertrec fetchers prefer to use HTTP/2.0 protocol if the host server supports it. If not gracefully degrading to HTTP/1.1 and HTTP/1.0, in that order. Along with the main content, if the content is of type HTML, all the referred CSS, JS and any other assets like images, fonts etc are also fetched. To support dynamic (ajax) content, all the JS scripts till onload event is executed. This gives the most accurate DOM content possible for indexing.
Content Extraction
If the content is of type HTML, the DOM content is extracted. Various pieces of the DOM like Title, meta keywords, description, etc are extracted separately. Structured data present on the page like price, reviews etc are extracted following the specification detailed at https://schema.org/docs/full.html
If the content type is other than HTML, like PDF, word etc, they are parsed using respective format aware content converters and the data from them extracted. Each document type supports various special fields like title etc.
Link Extraction
From the fetched URLs, any links that are mentioned on the pages are extracted. This is how more urls are discovered and crawled. Only links that are of method “GET” is extracted. No form submit action or POST action is performed. Hence the entire crawl operation is without any side effect on the website. If you have certain links that are not to be followed, use rel=”nofollow” as detailed in https://www.w3schools.com/TAGS/att_a_rel.asp.
Once links are discovered, the entire crawl iteration starts again with these additional urls to fetch.
Controlling Expertrec Crawl
Following section will explain different controls you have in the crawl and where and how to control them.
Seed URLs
These are the initial set of urls that are used to start the crawl. They can be set at https://cse.expertrec.com/csedashboard/addEditUrl
Sitemaps
Sitemaps are files that help in discovering the website urls. More details about sitemap is available at https://en.wikipedia.org/wiki/Site_map . Sitemaps can be added to the expertrec crawler at https://cse.expertrec.com/csedashboard/sitemapsettings
Expectrec crawlers pick up all the additional data available in the sitemap file. E.g. priority, images, and any other data. This data can be used for both ranking (say priority) or for display (like images, author, category) in the search results.
You can also instruct Expertrec Crawlers to skip the Link Extraction and completely rely only on the sitemap. “Crawl only sitemap” option is available at sitemapsettings.
Filters
Filters allow fine grained control over what gets crawled.
Robots.txt
Robots.txt is a way of specifying what gets included in the index of any search engine. This file will control both Expertrec and other public search engines like Google, Bing etc. If you want specific search engines to be controlled, for example, you want to allow all files to be crawled by Expertrec but not other public search engines, you can specify.
user-agent: expertrecbot
allow: *
Name of the Expertrec bot is “expertrecbot”
Google has standardized this format and is detailed in this document.
URL Params and duplicate pages
Certain websites are designed to pass in additional parameters to the page. The content of the page is identical even through this parameter might change. E.g. http://www.example.com/?t=1234 and http://www.example.com/ are identical. To avoid treating them as 2 different URLs, we can choose to ignore these additional parameters here.
If the pages are identical, but has two different URLs, it is advised to mark one of the URL as Canonical. E.g. If http://www.expertrec.com/ , https://www.expertrec.com/ and https://expertrec.com all serve the same page. Note the http=>https and the missing www. Then one of them is to be picked up as canonical url. Say https://www.expertrec.com/ and should be mentioned so in all the 3 URLs. More information about canonical from Google.
This is achieved by having something like <link rel=”canonical” href=”https://www.expertrec.com” /> to all the variations. This will help us keep only one copy of the page.
Different File types
You can optionally allow/disallow what kind of file types are to be crawled and indexed. Control them at filetypes.

Filter Urls
If the above set of controls are not enough, you can additionally use this advanced feature to control what gets crawled.
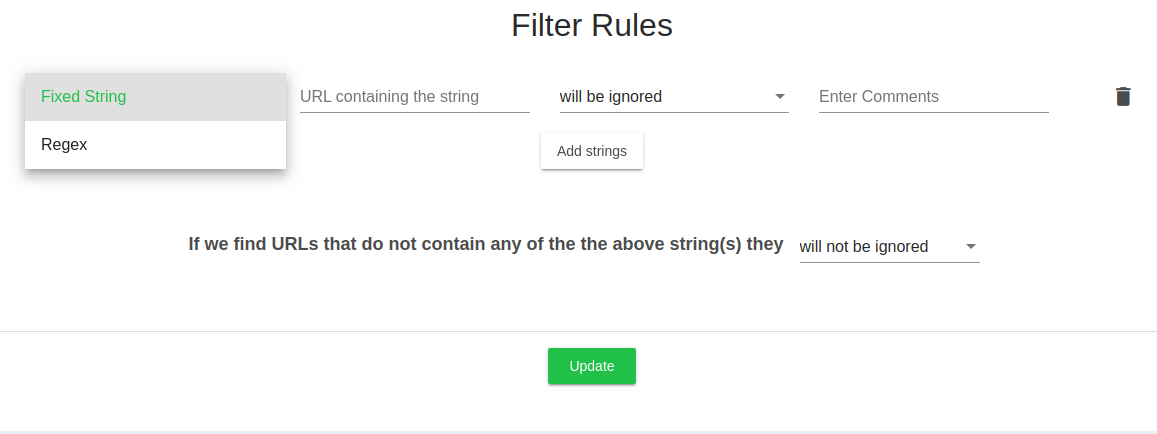
Here, you can mark urls which contains a string or a regex as to be crawled or to be ignored.
You can have multiple rules of inclusions and exclusions one below the other.
All urls that don’t match any of the rules will either be ignored or crawled based on the choice made in the below selection box.

Crawling protected/behind login pages
Expertrec crawlers are capable of logging in to your portal/website for a crawl. You can configure various forms of authentication for the same.
Whitelist IP
You can whitelist Expertrec’s crawler IPs to allow them passwordless access. If you do this, you need not configure any other forms of authentication. Enable this at https://cse.expertrec.com/csedashboard/authentication/whitelist
This will reveal a bunch of IPs that can be whitelisted.
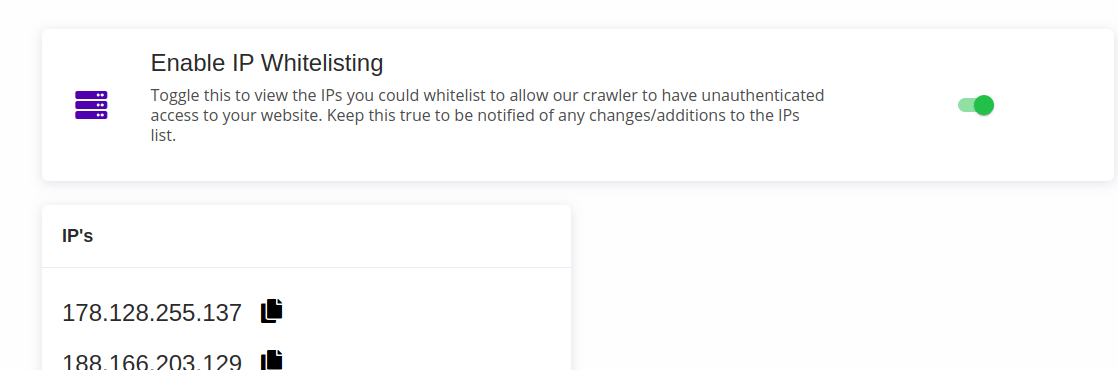
Learn more about IP whitelisting.
Authentication credentials
Expertrec Crawlers support 3 modes of authentication. Basic, NTLM and form based. You can enable authentication and select one of these modes used by your server.
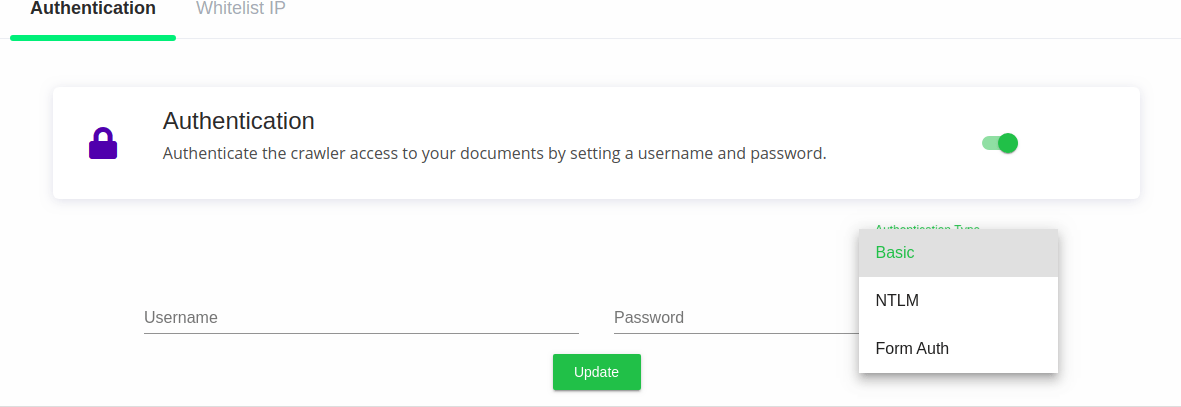
Settings are available at https://cse.expertrec.com/csedashboard/authentication/basic
Content Extraction – Advanced
In some pages, we would only want to index the main article. We would want to ignore the boilerplate headers and footers. This can be achieved by either enabling an automatic extraction at https://cse.expertrec.com/csedashboard/customfields/extractContent
If its performance is not satisfactory, you can control which pieces of the html page needs to be extracted by specifying the css selector of the main content.
