Why Searching for PDFs Is Hard
Standard search engines like Google primarily crawl and index HTML content. PDF files present unique challenges:- Content is locked inside the file: The text in a PDF is not part of the HTML page, so most crawlers skip it entirely or only read the file name and metadata.
- Scanned PDFs are images: Many PDFs – especially older documents – are scanned images with no extractable text layer, making them invisible to any search engine.
- PDFs behind logins or firewalls: Documents hosted on intranets, behind paywalls, or requiring authentication are completely unreachable by public search engines.
- No standardized structure: Unlike web pages that use headings, meta tags, and structured data, PDFs lack consistent formatting cues that help search engines rank and categorize content.
Methods to Search for PDF Files
1. Use Google’s filetype:pdf Operator
Google supports a special search operator that filters results to a specific file type. To search exclusively for PDF files, add filetype:pdf to your query. Here are some examples:filetype:pdf machine learning tutorial– Finds PDF documents about machine learning tutorials across the web.site:example.com filetype:pdf– Finds all indexed PDFs on a specific website.site:gov filetype:pdf tax forms 2024– Searches government websites for PDF tax forms.
2. Dedicated PDF Search Engines
Several specialized PDF search engines exist that focus exclusively on indexing document files. These tools aggregate PDFs from across the web and often provide preview functionality so you can scan documents before downloading. They are useful for broad PDF discovery but typically lack the ability to search within a specific website’s PDF collection.3. Site-Specific PDF Search with ExpertRec
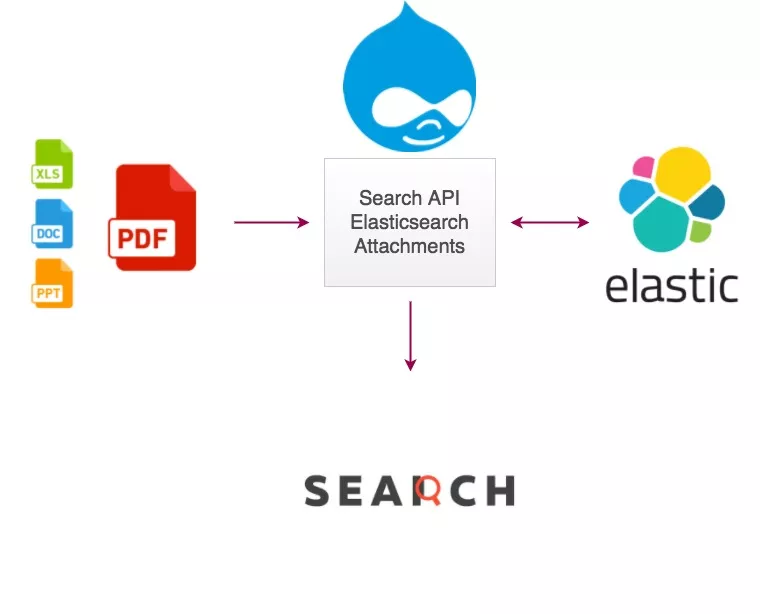
If you need to search for PDFs on a particular website – either your own or one you manage – a site search solution like ExpertRec is the most effective option. Unlike Google’s filetype operator, ExpertRec crawls and indexes the full text content inside each PDF, making every word searchable.How ExpertRec Indexes PDF Content
Most search tools treat PDFs as second-class content, indexing only the file name or page title. ExpertRec takes a different approach by performing full-text extraction from your PDF documents. Here is what that means in practice:- Full-text indexing: ExpertRec extracts and indexes every word inside your PDFs, so visitors can search for any phrase or keyword contained in the document – not just the title.
- Multiple document formats: Beyond PDFs, ExpertRec also supports DOC, XLS, and XML files, giving you a single search solution for all your hosted documents.
- PDFs behind login or firewall: ExpertRec can index PDFs that are not publicly accessible, including documents behind authentication or hosted on internal networks.
- Search results with context: When a visitor searches, results display relevant snippets from inside the PDF, helping users decide which document to open.
Step-by-Step: Make Your Website’s PDFs Searchable
Follow these steps to add PDF search to your website using ExpertRec:- Sign up and enter your URL: Go to https://cse.expertrec.com/?platform=cse and enter the URL of your website or the direct URL to your PDF files. ExpertRec will begin crawling automatically.
- Wait for the crawl to complete: The crawler will discover and extract text from all PDFs it finds on your site. You can monitor progress on the dashboard home page, where you can also preview search results in real time.
- Add the search code to your website: Once crawling is complete, copy the JavaScript snippet from the code section and add it to your website. This gives you a fully functioning search bar.
- Customize the experience: Adjust the appearance of the search bar, tweak the ranking algorithm, and enable features like voice search and autocomplete suggestions to match your site’s design and user expectations.
Tips for Better PDF Search Results
Whether you are searching for PDFs yourself or optimizing your site’s PDFs for search, keep these tips in mind:- Use descriptive file names: A file named
annual-report-2024.pdfis far more discoverable thandoc_final_v3.pdf. - Ensure PDFs contain text layers: Scanned documents without OCR processing are invisible to search. Use OCR tools to add a text layer before uploading.
- Include metadata: Set the title, author, and subject fields in your PDF properties – search engines use this information for indexing.
- Link to PDFs from your HTML pages: Search engines discover PDFs by following links, so make sure your documents are linked from your site’s pages.
You can use Google with the query ‘site:example.com filetype:pdf’ to find indexed PDFs on a specific website. For deeper search that covers the actual content inside PDFs, use a site search tool like ExpertRec that performs full-text extraction and indexes every word within the document.
A PDF search engine is a search tool that specifically indexes and retrieves PDF documents. Unlike general search engines that may only index PDF titles, a dedicated PDF search engine extracts the full text content inside PDF files, making every word searchable.
The filetype:pdf operator is a Google search command that filters results to show only PDF files. You add it to any search query, for example ‘filetype:pdf annual report 2024’, and Google will return only PDF documents matching your keywords.
Yes, with a search solution like ExpertRec that supports full-text PDF indexing. ExpertRec crawls your website, extracts the text content from PDF, DOC, XLS, and XML files, and makes them searchable through a customizable search bar on your site.
Ensure your PDFs contain actual text (not scanned images without OCR), host them with accessible URLs, and use a site search solution that supports PDF indexing. ExpertRec handles full-text PDF extraction automatically – sign up, enter your site URL, and add the search code to your pages.