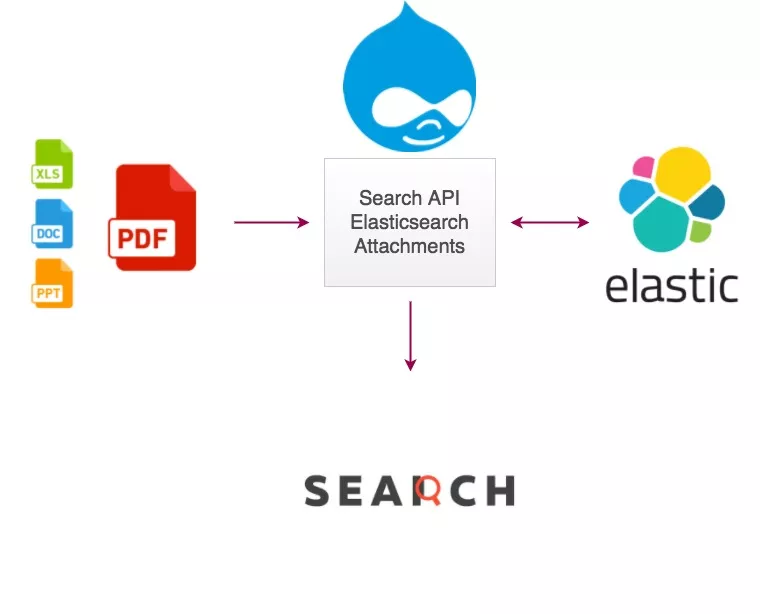


How to create a PDF full-text search engine using an elastic search?
Ingest Attachment Processor Plugin
The ingest attachment plugin lets Elasticsearch extract file attachments in common formats (such as PPT, XLS, and PDF) by using the Apache text extraction library Tika.
You can use the ingest attachment plugin as a replacement for the mapper attachment plugin.
The source field must be a base64 encoded binary. If you do not want to incur the overhead of converting back and forth between base64, you can use the CBOR format instead of JSON and specify the field as a bytes array instead of a string representation. The processor will skip the base64 decoding then.

Installation
This plugin can be installed using the plugin manager:
sudo bin/elasticsearch-plugin install ingest-attachment
The plugin must be installed on every node in the cluster, and each node must be restarted after installation.
This plugin can be downloaded for offline install from https://artifacts.elastic.co/downloads/elasticsearch-plugins/ingest-attachment/ingest-attachment-7.5.0.zip.
Removal
The plugin can be removed with the following command:
sudo bin/elasticsearch-plugin remove ingest-attachment
Example
The below code here Pdf to elastic search, the code extracts pdf and put into elastic search
import PyPDF2
import re
import requests
import json
import os
from datetime import date
class ElasticModel:
name = ""
msg = ""
def toJSON(self):
return json.dumps(self, default=lambda o: o.__dict__,
sort_keys=True, indent=4)
def __readPDF__(path):
# pdf file object
# you can find find the pdf file with complete code in below
pdfFileObj = open(path, 'rb')
# pdf reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# number of pages in pdf
print(pdfReader.numPages)
# a page object
pageObj = pdfReader.getPage(0)
# extracting text from page.
# this will print the text you can also save that into String
line = pageObj.extractText()
line = line.replace("\n","")
print(line)
return line
#line = pageObj.extractText()
def __prepareElasticModel__(line, name):
eModel = ElasticModel();
eModel.name = name
eModel.msg = line
return eModel
def __sendToElasticSearch__(elasticModel):
print("Name : " + str(eModel))
############################################
#### #CHANGE INDEX NAME IF NEEDED
#############################################
index = "samplepdf"
url = "http://localhost:9200/" + index +"/_doc?pretty"
data = elasticModel.toJSON()
#data = serialize(eModel)
response = requests.post(url, data=data,headers={
'Content-Type':'application/json',
'Accept-Language':'en'
})
print("Url : " + url)
print("Data : " + str(data))
print("Request : " + str(requests))
print("Response : " + str(response))
#################################
#Change pdf dir path
###################################
pdfdir = "C:/Users/muthali/Desktop/TemplatesPDF/SamplePdf"
listFiles = os.listdir(pdfdir)
for file in listFiles :
path = pdfdir + "/" + file
print(path)
line = __readPDF__(path)
eModel = __prepareElasticModel__(line, file)
__sendToElasticSearch__(eModel)
No code PDF search engine using expertrec
If you want to skip all the coding, you can just create a PDF search engine using expertrec.
How do I index a PDF as an Elasticsearch index?
Follow these steps to index a PDF file as an Elasticsearch index:
Install the PDF plugin for Elasticsearch: PDF indexing is not natively supported by Elasticsearch. You will need to install a plugin in order to index PDF files. The Elasticsearch PDF plugin is one such plugin. The plugin can be installed on your Elasticsearch server by downloading it from the official Elasticsearch website.
Make a text file out of the PDF file: You must convert the PDF file to a text file before you can index it. Apache PDFBox, Tika, and Poppler are just a few of the open-source libraries that you can use to convert a PDF file to a text file. To extract the text from the PDF file, you can use any of these libraries.
Create an index for Elasticsearch: You must create an Elasticsearch index to store the data after installing the PDF plugin and converting the PDF file to a text file. An index can be made with a program like Kibana or the Elasticsearch API.
The PDF file’s index: Finally, you can index the PDF file by sending an Elasticsearch PUT request with the text extracted from the PDF file and specifying the document type and index. To index a PDF file, for instance, you can use the cURL command listed below.
FAQs
How do you create an indexed link in a PDF?
Use PDF editing software that supports bookmarks and hyperlinks to create an indexed link in a PDF. The steps are as follows:
- In your PDF editing software, open the PDF file.
- Locate the item or text you want to link to. This can be accomplished with either the object selection tool or the text selection tool.
- Right-click the selected text or object and select “Create Hyperlink” or “Create Link” from the context menu.
- Depending on the kind of link you want to make, select “Go to a named position” or “Go to a page view” in the “Create Link” or “Create Hyperlink” dialog box.
- Select the page you want the link to point to if you select “Go to a page view.” You can likewise decide to zoom in or out on the page and select a particular region to show.
- You must first create a bookmark if you select “Go to a named position.” To do this, select the text or item that you need to bookmark, right-click and pick “Add Bookmark”. Click OK after giving the bookmark a name.
- In the “Make Connection” or “Make Hyperlink” discourse box, pick “Go to a named position” and select the bookmark that you recently made.To save the link, click OK.


