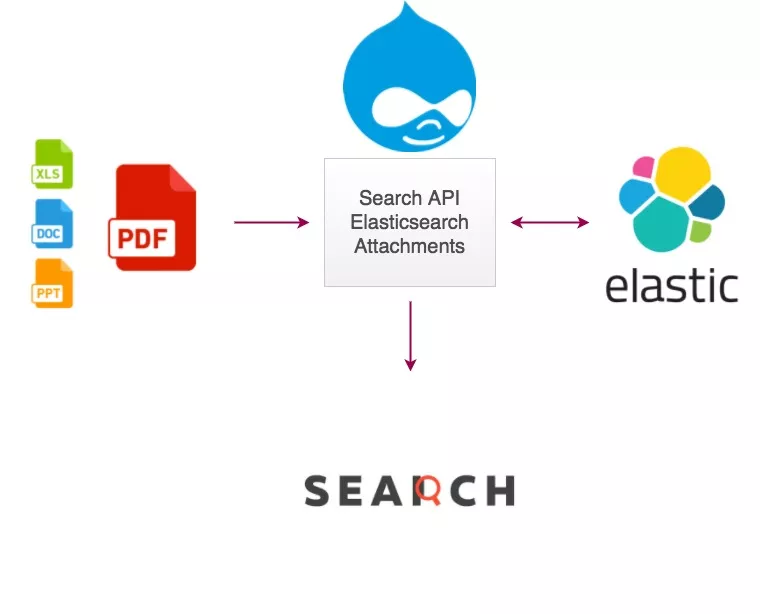
Read PDF search bar – How to implement? for more information.
Portable Document Format (PDF) is the most widely used and is the most effective way to transfer or store any information or data. It is Lightweight, loads quickly within fractions of seconds. And yes, the quality of content is intact, all Crisp and Clear. It is extremely popular and hence used all over the world.
The PDF format is mostly used everywhere, but the use of the Search feature in Word has helped users navigate through the documents easier. Some PDFs don’t support Text Search or sometimes the pdf text search is not working, hence we can not find any particular words from the content or even through the paragraphs. This is an issue if the document is bulky.
The most effective method to decide if a PDF is text content accessible
After opening the PDF, take a stab at looking for a word known to be in the record (ideally a word that shows up on a few unique pages) by clicking CTRL+F and entering the word you are searching in the Find box.
On the off chance that the message beneath shows up, the archive isn’t content accessible.
On the other hand, utilize the mouse to feature a word in the content. On the off chance that a solitary word can’t be featured and the whole page goes blue to demonstrate it is a picture, the content isn’t accessible.
The most effective method to make a PDF text content accessible

The accompanying directions apply to make PDF content accessible in Adobe Acrobat Professional or Standard:
- Snap on Tools > Text Recognition > In These File.
- The Recognize Text popup box opens. Select All pages, at that point click OK.
- The content acknowledgment procedure will continue page by page. Note: for an exceptionally long record the procedure may take a few minutes to finish.
- Providing content accessibility in various archives without a moment’s delay can be cultivated by choosing Tools > Text Recognition > In Multiple Files.
- The Recognize Text discourse box opens for including the records or organizers of reports to be made content accessible.

- At the point when every one of the documents or organizers is included, click OK to begin the content acknowledgment process. On the off chance that various records or organizers are chosen, content acknowledgment handling may take a seriously long time.

Have you ever wondered how to create site search for websites with pdf files. It is difficult to make a search engine that search the site for pdf files but it is very easy to do so with the help of Expertrec search.
Video: (To search Scanned documents in PDF)
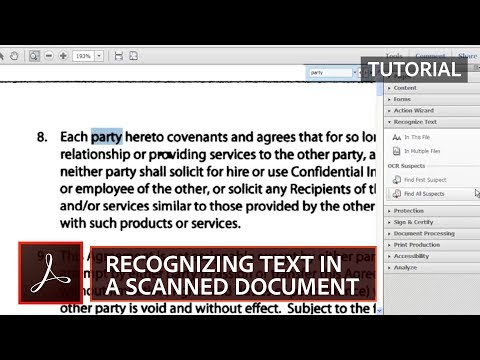


Unlocking the Full Potential of PDF Search: Common Issues and Solutions
In the ever-evolving landscape of digital information, PDF documents play a crucial role in sharing and preserving content. However, despite their widespread use, users often encounter challenges when trying to efficiently search through PDF files. In this blog post, we will explore common issues associated with PDF search functionality and provide insights into overcoming these hurdles.
1. Lack of Text Extraction
One primary reason for PDF search failures is the absence of properly extracted text. PDFs can contain both textual and non-textual elements, and sometimes the text within a document may not be readily accessible to search engines. This can occur due to the document being scanned, containing images, or having embedded fonts that hinder text extraction.
To address this, consider using Optical Character Recognition (OCR) technology to convert scanned images into searchable text. Additionally, optimizing PDF creation processes by ensuring text is properly embedded can enhance search accuracy.
2. Incomplete Indexing
Inefficient or incomplete indexing is another common obstacle to effective PDF search. Indexing is the process of cataloguing the content within a document to facilitate faster and more accurate searches. If the indexing process is incomplete or inaccurate, users may miss relevant information when conducting searches.
To enhance indexing, regularly update search engine algorithms and ensure that they are capable of handling the unique structure of PDF documents. Furthermore, consider implementing a robust indexing system that comprehensively captures and organizes the text within PDF files.
3. Limited Metadata Utilization
Metadata, such as document title, author, and keywords, can significantly impact search results. However, many PDF search issues arise from a lack of effectively utilized metadata. If this information is incomplete or irrelevant, it can impede users’ ability to locate specific documents or information within them.
Ensure that metadata is consistently and accurately populated during the PDF creation process. Additionally, invest in search algorithms that prioritize metadata when delivering search results, thus enhancing the overall user experience.
4. Insufficient Search Algorithm Complexity
The complexity of the search algorithm employed can greatly influence the accuracy of PDF searches. If the algorithm is too simplistic, it may struggle to handle the intricate structure of PDF files, leading to suboptimal search results.
Consider upgrading to more advanced search algorithms that can interpret and analyze the diverse elements within PDF documents. This includes recognizing different font styles, handling tables and charts, and understanding the hierarchical structure of the content.
5. Incompatibility with Document Versions
PDF files can exist in various versions, and search engines may encounter compatibility issues when attempting to index or search through files from different versions. This can result in missing content or inaccurate search results.
Regularly update your search engine software to ensure compatibility with the latest PDF standards. Additionally, provides users with guidelines on optimizing PDFs for search, encouraging them to adhere to current standards for better compatibility.
Conclusion
In conclusion, enhancing PDF search functionality involves addressing various technical challenges. By focusing on text extraction, indexing, metadata utilization, algorithm complexity, and version compatibility, you can significantly improve the accuracy and efficiency of searches within PDF documents. Remember that a proactive approach to these issues will not only benefit users but also contribute to a more seamless and rewarding user experience.