How PDF Search Works
Building a search engine for PDF files involves several technical steps that happen behind the scenes: 1. Crawling and Discovery: The search engine crawler visits your website and follows links to discover PDF files. It identifies files by their.pdf extension or MIME type. A good crawler will also discover PDFs linked from sitemaps or nested within directory listings.
2. Text Extraction: This is where PDF search gets complex. PDFs come in two main varieties:
- Text-based PDFs — Created from word processors or design tools. Text can be extracted directly from the document structure.
- Image-based (scanned) PDFs — Created by scanning physical documents. These require Optical Character Recognition (OCR) to convert the scanned images into searchable text.
Comparing PDF Search Approaches
There are several ways to search for PDF content, each with trade-offs:Google “filetype:pdf” Search
Google’sfiletype:pdf operator lets anyone search for publicly indexed PDFs across the web. It’s useful for finding PDFs on the open internet, but it has significant limitations for website owners: you cannot control ranking, customize the search interface, or include PDFs that sit behind authentication. Google also indexes PDFs on its own schedule, so newly uploaded documents may not appear for days or weeks.
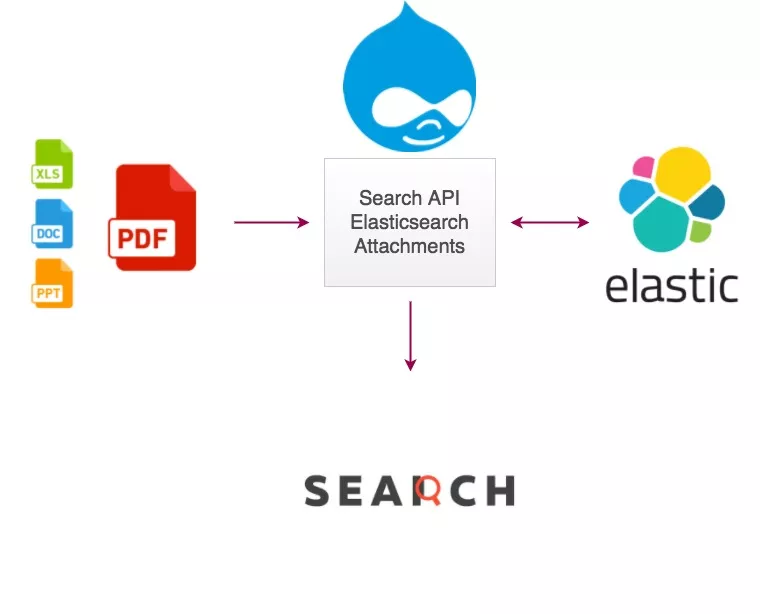
Self-Hosted Solutions (Elasticsearch, Solr)
Open-source search platforms like Elasticsearch and Solr can index PDFs using plugins such as Apache Tika for text extraction. These give you full control but require significant development effort, server infrastructure, and ongoing maintenance. For most website owners, this is overkill.ExpertRec PDF Search Engine
ExpertRec provides a managed search engine that handles PDF crawling, text extraction, indexing, and a customizable search UI — all without any coding. It integrates with your existing website and indexes PDFs alongside your regular web pages. Plans start at $49/month for content search, with search limits based on your selected plan.Creating a PDF Search Engine with ExpertRec
- Go to https://cse.expertrec.com
- Enter your website’s URL —

- Wait for the crawl to complete —

- Check the performance of your search using the live demo preview.
- Copy-paste the code to your website —

- Enable PDF search in your control panel — Go to Crawl → What to Crawl → File Types → Toggle PDF search to Yes → Save changes.






Supported File Types
ExpertRec doesn’t just index PDFs. The crawler supports multiple document formats including PDF, DOC/DOCX, XLS/XLSX, XML, and HTMLX. You can enable or disable each file type individually from the control panel, giving you fine-grained control over what gets indexed.Handling PDFs Behind Login
Many organizations keep sensitive PDFs behind authenticated areas — intranets, member portals, or client dashboards. ExpertRec’s crawler can access these pages by configuring login credentials or session cookies in the control panel. Visit the integrations and authenticated crawling page for step-by-step setup instructions.File Size and Configuration
ExpertRec handles standard PDF sizes commonly found on websites. You can configure crawl depth, specify URL patterns to include or exclude, and set re-crawl schedules to keep your search index up to date as new PDFs are added. The number of pages and documents indexed depends on your selected plan. Go to your demo link and check out how it performs. Here is a sample PDF search engine at work on one of our customer’s websites.

PDF Search Engine Use Cases
Academic and Research Sites: Universities and research institutions publish thousands of papers, theses, and journals as PDFs. A PDF search engine helps students and researchers find specific studies, citations, or topics across the entire document library without manually browsing through department pages. Legal Firms: Law offices manage vast collections of case files, contracts, court opinions, and regulatory documents — nearly all in PDF format. Enabling full-text search across these documents saves paralegals and attorneys hours of manual searching. Government Portals: Government websites often host public records, policy documents, meeting minutes, and permit applications as downloadable PDFs. Citizens searching for specific regulations or forms need a search engine that looks inside these documents, not just at page titles. Technical Documentation: Software companies, manufacturers, and engineering firms maintain product manuals, API references, datasheets, and compliance certificates as PDFs. A search engine for PDF files ensures that support teams and customers can quickly locate the exact information they need.Related PDF Search Guides
- Search website for PDF files
- How to create a Google PDF search engine
- Elasticsearch full text PDF search
- How to create and use a PDF search tool
Use a search solution like ExpertRec that automatically crawls and indexes PDF files on your website. It extracts text from PDFs, makes them searchable, and displays results with relevant snippets alongside your regular web pages. Setup takes about 5 minutes with no coding required.
Text-based PDFs (created from word processors) are indexed directly. Scanned PDFs require Optical Character Recognition (OCR) to convert images to searchable text. ExpertRec handles text-based PDF extraction automatically during crawling.
Google filetype:pdf searches publicly indexed PDFs across the entire web, with no control over ranking or display. A dedicated PDF search engine like ExpertRec indexes only your website’s PDFs, gives you a customizable search interface, supports PDFs behind login, and updates the index on your schedule.
ExpertRec supports multiple document formats including PDF, DOC/DOCX, XLS/XLSX, XML, and HTMLX. Each file type can be enabled or disabled individually from the control panel.
ExpertRec’s content search plans start at $49 per month, with search and indexing limits based on your selected plan. You can try the service and preview search results before committing to a plan.