

Introduction
Ngram, bigram, trigram are methods used in search engines to predict the next word in an incomplete sentence. If n=1, it is unigram, if n=2 it is bigram, and so on…
What is Bigram
This will club N adjacent words in a sentence based upon N
If the input is “ wireless speakers for tv”, the output will be the following-
N=1 Unigram- Output- “wireless” , “speakers”, “for” , “tv”
N=2 Bigram- Output- “wireless speakers”, “speakers for”, “for tv”
N=3 Trigram – Output- “wireless speakers for”, “speakers for tv”
BiGram example
Imagine we have to create a search engine by inputting all the game of thrones dialogues.

If the computer was given a task to find out the missing word after Valar ……. The answer could be “Valar Margulis” or “Valar dohaeris”. you can see it in action in the google search engine. How can we program a computer to figure it out?

By analyzing the number of occurrences in the source document of various terms, we can use probability to find which is the most possible term after valar.
BiGram Mathematics
The below image illustrates this- The frequency of words shows hat like a baby is more probable than like a bad
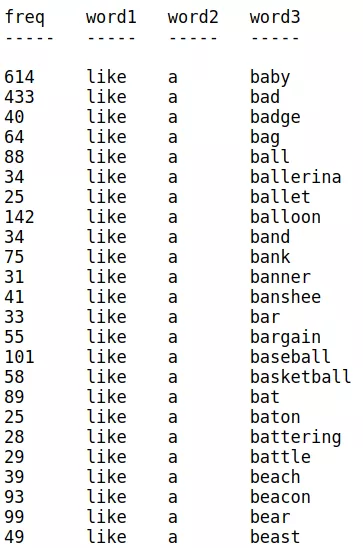
Let’s understand the mathematics behind this-

this table shows the bigram counts of a document. Individual counts are given here.

It simply means
- “I want” occurred 827 times in the document.
- “want want” occurred 0 times.
Now let’s calculate the probability of the occurrence of “I want English food”
We can use the formula P(wn | wn−1) = C(wn−1wn) / C(wn−1)
This means the Probability of want given chinese= P(Chinese | want)=count (want Chinese)/count (Chinese)
p(i want chinese food)
= p(want | i)* p(chinese | want) *p( food | chinese)
= [count (i want)/ count(i) ]*[count (want chinese)/count(want)]*[count(chinese food)/count(chinese)]
=(827/2533)*(6/927)*(82/158)
=0.00109
You can create your own N gram search engine using expertrec from here


