


Search engines have become an integral part of our digital lives, helping us find relevant information within seconds. Have you ever wondered how a search engine magically presents us with a list of results that match our queries? In this article, we will delve into the inner workings of search engines, exploring the underlying theory and mechanisms that enable them to deliver accurate and relevant search results.
Crawling and Indexing
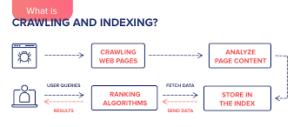
The first step in the search process is crawling. Search engines employ automated programs called crawlers or spiders to navigate the web and discover web pages. These crawlers follow links from one page to another, building an index of the web’s content. During the crawling process, they collect information about the pages, including URLs, metadata, and textual content.
Ranking Factors and Algorithms
Once the crawling phase is complete, search engines employ complex algorithms to rank and evaluate web pages based on various factors. While the exact algorithms used by search engines like Google are closely guarded secrets, some known ranking factors include relevance, authority, and user experience.
-
Relevance:
Search engines analyze the content of web pages and assess their relevance to specific search queries. They consider factors such as keyword usage, page titles, headings, and the overall context of the content to determine relevance.
-
Authority:
Search engines evaluate the authority and credibility of web pages by considering factors like the number and quality of backlinks. Pages with a higher number of reputable backlinks are considered more authoritative and are likely to rank higher in search results.
-
User Experience:

Search engines also take into account user experience signals, such as page loading speed, mobile-friendliness, and overall usability. Pages that provide a positive user experience are more likely to rank higher in search results.
Query Processing
When a user enters a search query, the search engine processes it to understand the user’s intent and retrieve relevant results. This involves several steps:
-
Tokenization:
The search engine breaks down the query into individual tokens, which are usually words or phrases.
-
Normalization:
The search engine normalizes the tokens by applying techniques like stemming (reducing words to their root form) and removing stop words (commonly used words like “the,” “and,” etc.) to improve search efficiency.
-
Index Matching:
The search engine compares the normalized tokens against its index to find web pages that contain relevant information. The index allows for quick retrieval of relevant pages based on the keywords or phrases in the query.
Relevance Ranking and Retrieval
Once the search engine identifies web pages that match the query, it applies its ranking algorithm to determine the order in which the results are displayed. The ranking algorithm considers various factors, including relevance, authority, and user experience signals discussed earlier. The search engine assigns a relevance score to each web page and presents the most relevant and authoritative results to the user.
Continuous Learning and Optimization
Search engines continually refine their algorithms and improve search results based on user feedback and evolving web trends. They employ machine learning techniques to analyze user behaviour and refine their ranking algorithms accordingly. This iterative process allows search engines to provide increasingly accurate and personalized search results over time.
Conclusion
Search engines have revolutionized the way we access and retrieve information on the internet. By leveraging the power of crawling, indexing, ranking algorithms, and query processing, search engines can efficiently find and present relevant results to users. Understanding the theory and mechanics behind search engines helps us appreciate the complexity involved in delivering accurate and valuable search results. As technology advances, search engines will continue to evolve, providing us with even better search experiences in the future.


