

Google site search was the go-to product for a lot of website developers to add a custom search engine to their website. But Google decided to sunset the product in April 2017 and shut down GSS completely a year later. This has left a lot of website owners looking for alternatives to Google Site Search. While not everyone utilizes a website’s search functionality, those who do are looking for something specific and expect to find answers quickly and easily. If people are on your website and using the search feature, they are obviously interested in what you have to say or in what you’re selling, so catering to them is important. If your search function is weak, users may leave your site, meaning you’re losing a customer – and that is simply unacceptable.
With GSS no longer an option, we’ll take a look at how it worked, why it is hard to replace, and also take a look at a few alternatives.
How does Google Site Search Engine work?
You login to google site search console, enter your URL and bam! you have a ready site search engine code to add to your website in minutes. How did Google do this?
Google is a web search engine. Google Site Search is a product where one can use Google Web Search for powering the site search.
We will take a look at-
- How Google Web Search works
- What components of Google Web Search are re-used for Site Search? We will try and cover how this is implemented behind the scene.

Source: Tham Yuen-C & Quek Hong Shin
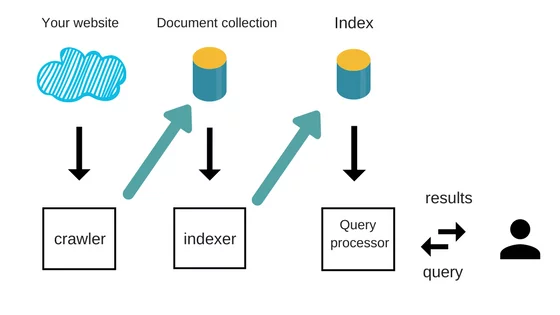
There are roughly 3 major components that makes the google site search suite-
Google site search Crawler –
What is a crawler?- A crawler is a software program that visits websites and reads their pages and creates entries for a search engine index. These are also called bots or spiders. The web crawler starts with an initial list of URLs crawl
Crawler main characteristics-
Google’s crawler is a highly resilient one and it has a great balance between latency and throughput.
Latency – the amount of time it takes for a newly discovered page to be made available on the results page. Throughput- the number of pages that get re-crawled and updated in the search results.
If we crawl one page at a time and update the index, it will be having a much lower Latency, but the Throughput will suffer greatly. Google will not be able to crawl the entire web, one page at a time. If we update the index every 1million pages, it might be too late for a news page to be made available in the results. Google has a very elaborate setup to handle this (probably another article down the line). Another important aspect one has to consider when building a crawler is not to overload the web server in which the pages are hosted. This is called politeness. If the server is loaded, the bots give it enough breathing time between requests so that regular users are not affected by the crawl. When we built our crawler(Expertrec Bot), we have given it a great amount of consideration.
Indexer – The crawler might have fetched a variety of documents. Html, PDF, Word file, etc. They all need to be indexed so that they can come in the search results. Most of the books have an index at the end.

Having this index helps us quickly find a word in the book. e.g. in the above Index, the word ABC has occurred on pages 164 and 321. Creating this data of Word=>Location is the job of an Indexer. To facilitate various search operations, the Index has to be built accordingly. Google’s indexer not only has to be CPU efficient, but the generated index size also has to be quite small. If you created a bloated index, you won’t be able to hold the index for billions of documents. Our indexer was built to handle only 10s of millions of documents (not Billions) as Google. Yes, we know we might have to re-write it sooner 🙂
- Search operation – Once the Index is built, a query (search term) can be made to retrieve the search results. Search results for a multi-word query like “Site Search Replacement” happens by looking up “Site”, “Search” and “Replacement” in the index. The list of documents with each of the words will be retrieved from the index. e.g. if “Site” is present in documents [1,2,3,4,5,6], “Search” is present in documents [2,4,6,8] and “Replacement” is present in documents [3,6,9,12]. The intersection of the above 3 sets gives the list of documents with all the 3 words. i.e. Document [6] has all of “Site”, “Search” and “Replacement” words in it. Hence is the most relevant result from the Information retrieval point of view (IR score). There are various other relevance scoring mechanisms that are together considered when the results are created. Google claims to be using more than 200 such signals, including but not limited to “page rank”, “domain authority”, “recency”, “TF/IDF”, prominence of the words in the document, etc.
In Google Site Search, in addition to retrieving the search results, (the set intersection operation) we talked about in the above paragraph, there is a list that has the documents that are present only on your website. i.e. if your site is wikipedia.org and documents [1,..100] are present in wikipedia.org, then before returning the search results, Google does a set intersection with this set as well, so that only documents in 1-100 alone are returned (thereby only wikipedia.org results come in the results). By leveraging their existing crawler, indexer and search server, Google just made a minimum change to support Google Site Search and have thereby powered many many site searches.
Why is Google Site Search hard to replace?
Users are left wondering what to do next as Google Site Search has been shut down. GSS was an easy to use solution. And people trusted it to work giving them a Google level search service on their website. It gave features like multi-language support, Google’s ranking algorithm and more and could be integrated with ease. Since developing a search from scratch is not the best way to go about it and getting the quality that Google provides is not a simple task, GSS replacement can be hard to find. Google’s own solution to this is Google Custom Search. It provides a similar feature set for free but will display ads on your website.
Google Site Search Alternatives
Among the myriad of alternatives out there, only a handful can be termed as a like for like replacement to GSS. Even Google’s own custom search is not a great fit for people who were previously on-site search. As an alternative I suggest ExpertRec. With no ads and a fully customizable ranking algorithm, it gives all the features of GSS and more while not displaying any ads like GCS. Other additional perks include voice search, which is also pretty rare among other alternatives. Here’s how you can add ExpertRec’s site search to your website:
- Navigate to https://cse.expertrec.com/newuser?platform=cse and signup with your Google ID.
- Enter your website’s URL when prompted. You can select a server location near you and add the URL of your sitemap if you wish to. These will be auto-detected otherwise.
- You can play around with the settings and customize the UI as the crawl runs. Once it is complete, you can check out a fully functional demo before taking the search to your website.
- You can take the search to your website with little to no effort. All you need to do is to paste the code snippet available on the dashboard on your website.
ExpertRec comes with more customization options that you can explore. You can read this article to find a more detailed guide on the installation and configuration.


