

Introduction: What Are N-Grams in NLP?
If you have ever used a search engine and noticed it predicting what you are about to type, you have seen n-grams at work. An n-gram is a contiguous sequence of n items (usually words) extracted from a given text or speech sample. N-grams form one of the foundational concepts in Natural Language Processing (NLP), computational linguistics, and modern search engine technology.
Search engines like Google rely heavily on n-gram analysis to power features such as autocomplete, spell correction, and query understanding. When Google suggests “wireless speakers for tv” after you type just “wireless sp…”, it is using statistical models built on billions of n-grams extracted from web pages and past search queries.
In this guide, we will explain unigrams, bigrams, and trigrams with clear definitions, practical examples, a Python code tutorial, and a look at how n-gram techniques improve search relevance.
N-Gram Definitions: Unigram, Bigram, and Trigram
The value of n in “n-gram” simply refers to the number of consecutive words (or tokens) grouped together. Here are the three most common types:
Unigram (n = 1)
A unigram is a single word taken from a text. Unigram analysis treats each word independently without considering context. For the sentence “wireless speakers for tv”, the unigrams are:
- “wireless”
- “speakers”
- “for”
- “tv”
Bigram (n = 2)
A bigram (also called a digram) is a pair of two consecutive words. Bigrams capture basic word-pair context, making them far more useful than unigrams for understanding phrases. The bigram meaning is simple: slide a window of size 2 across the text, one word at a time. For “wireless speakers for tv”, the bigrams are:
- “wireless speakers”
- “speakers for”
- “for tv”
Trigram (n = 3)
A trigram groups three consecutive words together, providing even richer context. For the same input “wireless speakers for tv”, the trigrams are:
- “wireless speakers for”
- “speakers for tv”
Bigram Example: Predicting Words in Game of Thrones
Imagine we have to create a search engine by inputting all the Game of Thrones dialogues.

If the computer was given a task to find out the missing word after Valar ……. The answer could be “Valar Margulis” or “Valar dohaeris”. You can see it in action in the Google search engine. How can we program a computer to figure it out?

By analyzing the number of occurrences in the source document of various terms, we can use probability to find which is the most possible term after “Valar.” This is exactly how bigram-based language models work – they estimate the probability of a word given the word that came before it.
Bigram Mathematics: How Probability Works
The below image illustrates this – the frequency of words shows that like a baby is more probable than like a bad:
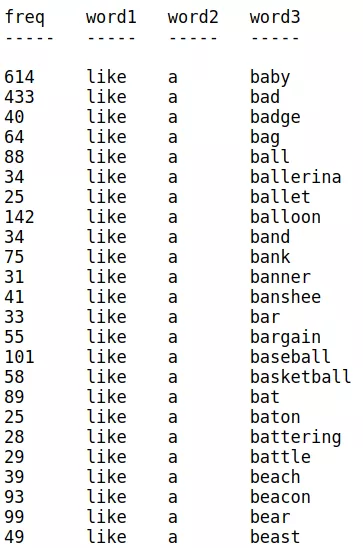 Let’s understand the mathematics behind this –
Let’s understand the mathematics behind this –

This table shows the bigram counts of a document. Individual counts are given here:

It simply means:
- “I want” occurred 827 times in the document.
- “want want” occurred 0 times.
Now let’s calculate the probability of the occurrence of “I want English food”.
We can use the formula P(wn | wn−1) = C(wn−1wn) / C(wn−1)
This means the Probability of “want” given “Chinese” = P(Chinese | want) = count(want Chinese) / count(Chinese)
p(I want Chinese food)
= p(want | I) × p(Chinese | want) × p(food | Chinese)
= [count(I want) / count(I)] × [count(want Chinese) / count(want)] × [count(Chinese food) / count(Chinese)]
= (827/2533) × (6/927) × (82/158)
= 0.00109
Practical Applications of Bigrams and N-Grams
N-gram analysis is used across many areas of technology. Here are the most important real-world applications:
Search Engines
- Autocomplete & Search Suggestions: When you start typing a query, the search engine uses bigram and trigram frequency data to predict and suggest the most likely completions.
- Spell Correction: Character-level bigrams help detect and correct misspellings. If a user types “wirless spekers,” the engine compares character bigrams against known correct words to suggest “wireless speakers.”
- Query Understanding: Bigram analysis helps search engines distinguish between different meanings of the same word by looking at surrounding context. For example, “apple pie” vs. “apple store” are identified as different intents through bigram patterns.
Natural Language Processing (NLP)
- Language Modeling: Bigram and trigram models estimate the probability of word sequences, enabling applications like machine translation and speech recognition.
- Sentiment Analysis: Bigrams such as “not good” or “very bad” carry meaning that individual unigrams miss, making them critical for accurate sentiment classification.
- Text Classification: Spam filters and topic classifiers use n-gram features to categorize documents more accurately than single-word analysis alone.
Text Analysis & Data Science
- Keyword Extraction: Extracting the most frequent bigrams from a document reveals key topics and themes.
- Plagiarism Detection: Comparing n-gram fingerprints between documents can detect copied content efficiently.
N-Grams in ExpertRec Search
ExpertRec uses n-gram-based techniques to power its AI-powered site search features, including smart autocomplete suggestions and typo-tolerant search. These n-gram models analyze your site’s content to deliver relevant suggestions as users type, improving both search accuracy and user experience.
Python Code: How to Generate Bigrams from Text
Here is a simple Python example that shows how to generate unigrams, bigrams, and trigrams from a sentence:
def generate_ngrams(text, n):
"""Generate n-grams from input text."""
words = text.lower().split()
ngrams = []
for i in range(len(words) - n + 1):
ngram = ' '.join(words[i:i + n])
ngrams.append(ngram)
return ngrams
# Example text
text = "wireless speakers for tv"
# Generate unigrams, bigrams, and trigrams
unigrams = generate_ngrams(text, 1)
bigrams = generate_ngrams(text, 2)
trigrams = generate_ngrams(text, 3)
print("Unigrams:", unigrams)
# Output: ['wireless', 'speakers', 'for', 'tv']
print("Bigrams:", bigrams)
# Output: ['wireless speakers', 'speakers for', 'for tv']
print("Trigrams:", trigrams)
# Output: ['wireless speakers for', 'speakers for tv']
You can also use the NLTK library for a more concise approach:
from nltk import ngrams
text = "wireless speakers for tv"
words = text.split()
bigram_list = list(ngrams(words, 2))
print("Bigrams:", [' '.join(bg) for bg in bigram_list])
# Output: ['wireless speakers', 'speakers for', 'for tv']
Comparison Table: Unigram vs Bigram vs Trigram
| Type | Window Size (n) | Example (from “I love coding in Python”) | Primary Use Case |
|---|---|---|---|
| Unigram | 1 | “I”, “love”, “coding”, “in”, “Python” | Bag-of-words models, basic word frequency analysis |
| Bigram | 2 | “I love”, “love coding”, “coding in”, “in Python” | Autocomplete, phrase detection, sentiment analysis |
| Trigram | 3 | “I love coding”, “love coding in”, “coding in Python” | Language modeling, machine translation, context-rich predictions |
Get Started with N-Gram Powered Search
You can create your own n-gram powered search engine using ExpertRec from here. ExpertRec’s site search plans start at $49/mo and include AI-powered autocomplete, typo tolerance, and relevance tuning built on n-gram techniques.
Add Expertrec Search to your website
A bigram is a sequence of two consecutive words or characters extracted from a text. For example, in the sentence ‘I love coding’, the bigrams are ‘I love’ and ‘love coding’. Bigrams are widely used in language modeling, autocomplete systems, sentiment analysis, and search engines to capture word-pair context that single words miss.
A unigram (n=1) is a single word, a bigram (n=2) is a pair of two consecutive words, and a trigram (n=3) is a sequence of three consecutive words. These are all types of n-grams used in natural language processing. Bigrams and trigrams capture more context than unigrams, making them better for tasks like phrase detection and language modeling.
Search engines use bigrams to power autocomplete suggestions, correct spelling errors, and understand query intent. By analyzing the frequency of word pairs across billions of documents, search engines can predict what a user is likely searching for and return more relevant results. Bigram analysis also helps distinguish between different meanings of ambiguous queries.
A bigram is defined as a contiguous sequence of two items (typically words) from a given sample of text or speech. In the context of NLP and computational linguistics, bigrams are used to build statistical language models that predict the probability of a word based on the preceding word. The bigram model is one of the simplest and most widely used n-gram models.
You can generate bigrams in Python by splitting text into words and then pairing consecutive words using a loop or list comprehension. For example: words = text.split(); bigrams = [words[i] + ‘ ‘ + words[i+1] for i in range(len(words)-1)]. Alternatively, you can use the nltk.ngrams() function from the NLTK library for a more concise solution.


