

What is TF-IDF
TF stands for term frequency. IDF stands for inverse document frequency. TF-IDF stands for the multiplication between Term frequency and inverse data frequency.
Why are these important? These calculations help us in finding out the important words in a text which gives us an idea about what the document is talking about. It helps in removing words like “the”, “is ” which are known as stop words. These are used widely in search and recommendation engines.

TF- Term Frequency-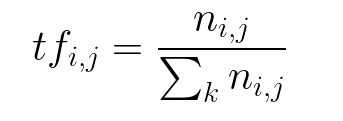
TF(w)=(Number of times word w appears in a document/ total number of words in the document)
IDF- Inverse document frequency-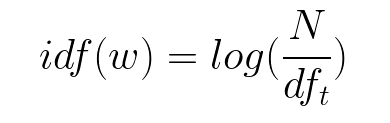
IDF(w)= log (total number of documents/ Number of documents with word w)
TF-IDF is the multiplication of Term frequency and inverse document frequency.
TF IDF example:
Let us take two sentences
sentence 1– the earth is the third planet from the sun
sentence 2– the earth is the largest planet
We calculate the TF IDF scores as shown in the image below.
As you can see
TF IDF is zero for stop words which don’t help in understanding what a document is talking about-
is
the
from
TF IDF is non zero for important words such as as-
earth
Jupiter
Sun
largest
third
As we input more documents into the TF IDF system, the accuracy of the TF IDF calculation increases.
Here is an open-source library for implementing TF IDF

If you are looking to implement a TF IDF based search engine, you can use the below button.


