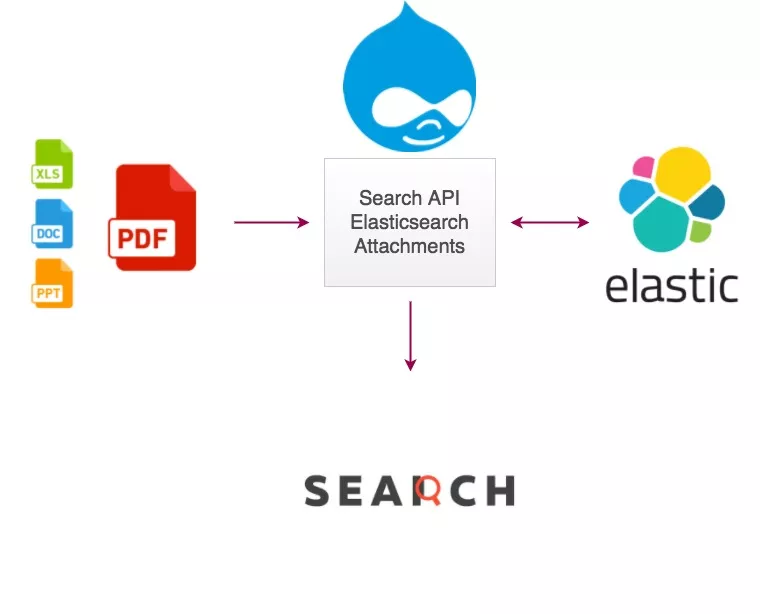
PDF search is an important feature on all websites. Many websites have a lot of documents and guides in the form of PDFs. While users are using the site search function in your website, they might want to discover content within PDFs. It is important that the search engine on your website has the capabilities to crawl your website’s PDFs.

Why PDF search is important?
- A lot of important information is within PDFs in the form of manuals and guides.
- PDFs have a higher engagement with users in terms of views and downloads that can help in higher conversion rates.
What content has to be indexed or extracted from PDFs?
- The text within PDFs.
- Images within PDFs.
- Metadata of the PDF
- Title of the PDF.
- URL.
- Description.
- Date of publishing.

Challenges while indexing PDFs-
- Encrypted PDfs– Some PDFs may have encrypted content through which search engine crawlers might not be able to pass through. You might want to make available such PDFs to a given set of your website audience. Using a pdf search engine like Expertrec, you will be able to specify a set of passwords against a given set of PDF URLs which will let the search engine crawlers pass through the encryption.
- Extracting content within images inside PDFs- A lot of PDFs have images inside them. Most search engine crawlers ignore images inside PDFs. Advanced search engines make use of OCR (optical character recognition) to extract the text inside images and make them available for searching.
- Generating a search snippet-When a PDF appears in a search engine result, there is a search engine feature called snippet which is a piece of text that gives an idea of what is inside the PDF that is relevant to the user’s search query. Generating a relevant snippet for a search query is an area where many search engines falter. Also, different websites have different requirements on what to show in the snippet area. Expertrec’s search service gives you control over the text displayed in the PDF search snippet.
- Generating a screenshot for the search engine- It is very useful to present to your users a screenshot of a PDF that gives a preliminary idea of what is inside the PDF. The challenge is that the PDF search screenshot should be relevant to the user’s search query. Many search engines just take a screenshot of the first page and display it in the search engine results. Advanced search engines take into user behavior and pick up the right portion of the PDF and take a screenshot to display to the user.
- Missing PDFs to index- Some PDFs are not linked well on some websites. Due to this, search engine crawlers can miss some PDFs. To avoid this, it is better to have a PDF sitemap and add it to your search engine control panel. This will ensure that all your PDFs are crawled. Another way is to list all your PDFs in a single page. If you are using wordpress, you can use the simple file list extension. https://wordpress.org/plugins/simple-file-list/
- Size of PDFs- Most search engines put an upper limit on the size of PDFs indexed. Usually, PDFs are of higher size. Sometimes, the most important PDFs on your website might be of bigger size and it might be counterproductive to your business to put an upper limit on the PDF. Discuss this with your search engine provider and choose what type of PDFs are to be indexed.
- Number of PDFs to be indexed-One of our customers wanted to index 100,000 PDFs. Handling a large number of PDFs might be a bit more complex and search engines can falter while indexing a lot of PDFs periodically. Ask your search engine provider for the maximum amount of documents they can help with.
- Handling new PDFs-When a new PDF is added to your website, it is important that your search engine finds it and indexes it as soon as possible. Your search engine recrawl frequency is important in this since this determines when your new PDFs are crawled. Having a PDF sitemap can also help in this cause.
How to create a search engine and index PDFs?
Prerequisites-
- Have a PDF sitemap or have all the PDFs listed on a page.
- The website should be live.
Steps-
- Go to PDF search engine creator.
- Sign up with your Gmail ID.
- Enter your PDF sitemap URL.
- Choose your nearest data center.
- Initiate your website crawl.
- Go to filetypes and enable PDF search.
- Go to code and add it to to the head section of your website.
This will help add PDF search capabilities to your website.
If you are looking to build your own PDF search engine, you can use open-source tools such as Apache Tika.
The Apache Tika toolkit detects and extracts metadata and text from over a thousand different file types (such as PPT, XLS, and PDF). All of these file types can be parsed through a single interface, making Tika useful for search engine indexing, content analysis, translation, and much more. You can find the latest release on the download page. Please see the Getting Started page for more information on how to start using Tika.
The Parser and Detector pages describe the main interfaces of Tika and how they work.
If you’re interested in contributing to Tika, please see the Contributing page or send an email to the Tika development list.
Tika is a project of the Apache Software Foundation, and was formerly a subproject of Apache Lucene