Building Web crawler Search Engine is an extremely complex engineering project. Trying to build a web crawler can provide can give a great understanding of how a web crawler search engine works. There are multiple huge complex components involved in building a search engine crawler.
To build a complete search engine you would need the following components
What is Web Crawler?
There are around 1.88 billion websites on the internet. The crawler visits each and every one of the websites and collects information about each website, and each page in a website periodically. It does this job so that it can provide the required information when a user asks for it.
Crawler architecture
Here is a typical crawler architecture.
Crawling Process
How does a Web Crawler work?
Web crawler works by first visiting a website root domain or root URL say https://www.expertrec.com/custom-search-engine/. It looks for robots.txt and sitemap.xml. robots.txtprovides instruction for the crawler, web crawler instructions like not to visit a particular section of the website using disallow section. Website creators use this file to give instructions to search engines like what kinds of information can be collected or gathered.
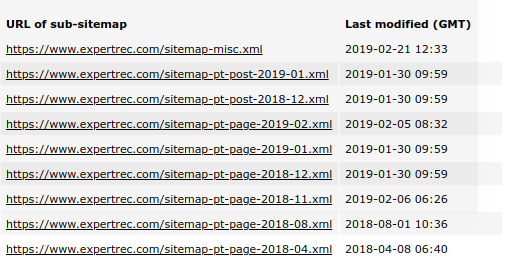
After completing the visit of robots.txt, it looks for sitemap.xml. Sitemap.xml contains all the URLs of the website and also instructions to search engines or crawlers on how frequently that particular page should be crawled. A sitemap is mainly used for easy link findability and to prioritize the contents in the website that should be crawled.
What is Search Index?
Once the crawler crawls the web pages in a website, All the information like Keywords in the website, meta-information (information about) a page like meta description, etc are extracted and put in an index. This index can be compared to an index that can be found in every book, that can be used to lookup up the exact page number and hence the information about the keyword to retrieve results faster.
What is Search Ranking?
Every time when a user searches for information, the search results are produced by looking up the index and many other signals like your location from which you query, These extra signals help in producing better search results
Web Search User interface
Most users search in browsers or mobile apps through the search engine interface. This is usually built using JavaScript.
Some pointers to keep in mind while designing a good WebCrawler for searching the web.
Ability to download huge web pages
Less time to download web pages
Consume optimal bandwidth.
Handle HTTP 301 and HTTP 302 Redirects– The crawler should be able to handle such pages.
DNS caching– Instead of doing a DNS lookup every time, the crawler should cache the DNS. This helps to reduce the crawl time and internet bandwidth used.
reducing dns caching
Multithreading–Most crawlers launch several “threads” in order to download web pages in parallel. Instead of a single thread downloading the files, you can use this approach to parallel fetch multiple pages.
multithreaded webcrawler search engine
Asynchronous crawl– Asynchronous crawling, since only one thread is used to send and receive all the web requests in parallel. This saves RAM and CPU usage. Using this we can crawl more than 3,000,000 web pages while using less than 200 MB of RAM. Using this we can achieve a crawl speed of more than 250 pages per second.
Duplicate detection- The crawler should be able to find duplicate URLs and remove them. When a website has more than one version of the same page, the Crawler should find the authoritative page of all the versions even if the website creator does not provide a canonical URL for the web page. Canonical URLs are the authoritative URL that search engines should look for when the website creators create multiple versions of the same web page. Website creator marks canonical URL by adding link tag in all the duplicate pages as follows.
Handing Robots.txt – The crawler should read the settings in the robots.txt for crawling the pages. Some pages (or page patterns) will be marked as Disallow and these pages should not be crawled. Robots.txt will be found at website.com/robots.txt
robots.txt
Sitemap.xml- Sitemap is a link map of the website. It has all the URLs that need to be crawled. This makes the crawling process simpler.
sitemap
Crawler policies-
selection policywhich states which pages have to be downloaded.
are-visit policythat states frequency to look for changes in the website.
apoliteness policy How fast the website can be crawled (so that website load does not increase)
aparallelization policyInstructions for distributed crawlers.
System Design Primer on building a Web Crawler Search Engine
Here is a system design primer for building a web crawler search engine. Building a search engine from scratch is not easy. To get you started, you can take a look at existing open source projects like Solr or Elasticsearch. Coming to just the crawler, you can take a look at Nutch. Solr doesn’t come with a built-in crawler but works well with Nutch.
What are some open source web crawlers you can use
Expertrec is a search solution that provides a ready-made search engine ( crawler+parser+indexer+Search UI ). You can create your own at https://cse.expertrec.com/?platform=cse
FAQs
How do search engine crawlers work?
Search engines use their own web crawlers to get information.
Search engines begin their crawling by downloading its robots.txt file which contains some rules like what pages should search engines crawl or should not crawl on the website.
Robots.txt file may also give information about sitemaps that give lists of URLs that the site wants a search engine to crawl.
Search engine crawlers use algorithms and rules to determine how a page should be recrawled frequently and how many times it should be indexed.
How to build a search engine web crawler?
Add one or several URLs to be visited.
Pop a link from the URLs to be visited and add it to the visited URLs thread
Fetch the page’s content and rub the data you’re interested in with the scraping bot API
Describe all the URLs present on the page, and add them to the URLs to be visited if they match the rules you’ve set and do not match any of the visited URLs.
Repeat steps 2-4 until the URLs to be visited list is empty.
What is the difference between a web crawler and a search engine?
Both the web crawler and the search engine are actually part of the same system
Search engine like Google, yahoo,Expertrec, etc facilitates the provision of information. A search engine (in addition to sending millions of web crawlers out to collect information) also indexes this information so that it will be organized to allow easy retrieval and provides interfaces to allow users or other programs to query the indexed information for specific results.
The retrieval system is used by the search engine to return results when someone asks for them.
The web crawler gathers the data, data which is then saved in some kind of retrieval system
a web crawler performs the search operation for the query given by the user. The crawler crawls different web pages on WWW which matches the search query and indexes the web pages using ranking algorithms and provides it to the user as a search result.
How do detect and verify search engine crawlers?
Detect the search engine crawler That the request has to be signed with its name, called User Agent.
First, we need to verify a request’s source properly, you need to check the IP address from which the request was made. Verify the search engines provide IP lists or ranges. we can verify the crawler by matching its IP with the provided list and performing a DNS lookup(It is a method of connecting a domain to an IP address) to connect the IP address to the domain name.